K8S进阶
K8S 进阶
资源负载,进阶实战
Pod
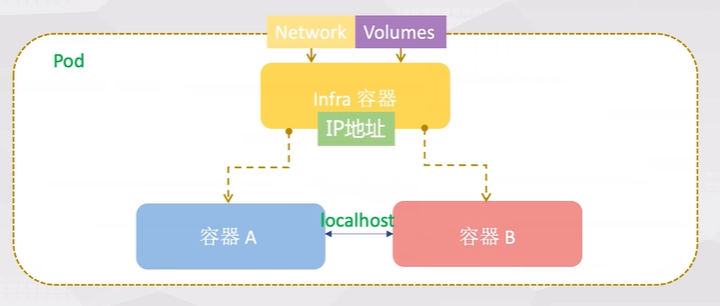
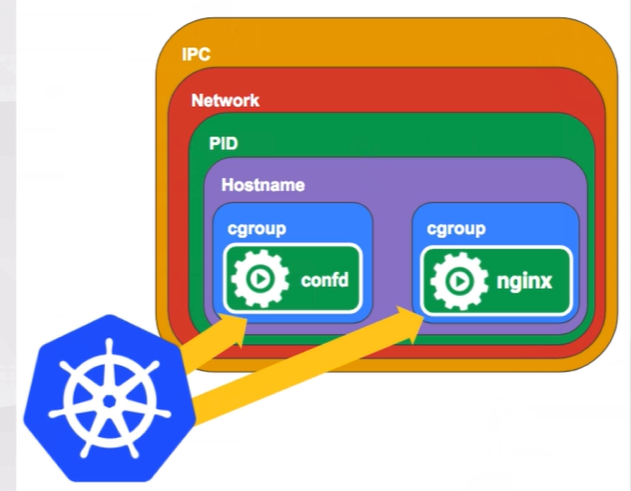
Pause容器
每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷.
原则上,任何人只需要创建一个父容器就可以配置docker来管理容器组之间的共享问题。这个父容器需要能够准确的知道如何去创建共享运行环境的容器,还能管理这些容器的生命周期。为了实现这个父容器的构想,kubernetes中,用pause容器来作为一个pod中所有容器的父容器。这个pause容器有两个核心的功能:
- 第一,它提供整个pod的Linux命名空间的基础。
- 第二,启用PID命名空间,它在每个pod中都作为PID为1进程,并回收僵尸进程。
在ghost容器中同时可以看到pause和nginx容器的进程,并且pause容器的PID是1。而在kubernetes中容器的PID=1的进程即为容器本身的业务进程。
- 纽带,将所有容器连接起来
- 最先启动
- 暂停
- 为pod内的容器创建共享的网络/存储
- 只允许 网络和存储。其他4种资源能共享吗?
kubernetes中的pause容器主要为每个业务容器提供以下功能:
-
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
-
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
-
IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
-
UTS命名空间:Pod中的多个容器共享一个主机名;Volumes(共享存储卷):
-
Pod中的各个容器可以访问在Pod级别定义的Volumes。
Namepsace
- 使用一个k8s集群划分多个虚拟集群
- 多租户、多产品线
- 按照团队划分(基础服务,业务中台,用户中心)
- 按照业务线划分(用户产品,BPIT)
- 区分环境(dev,test)
- 资源对象的隔离
- Ns间有条件不可见
- 资源数量的隔离(resource quota)
- cpu、内存的是用配额
- 更细粒度控制
Resources
一个进程可以使用它所运行的物理机器上的所有资源,从而使其他进程无法获得资源。为了限制这一点,Linux有一个称为cgroups的特性。进程可以像在命名空间中一样在cgroup中运行,但是cgroup限制了进程可以使用的资源。这些资源包括CPU、RAM、块I/O、网络I/O等。CPU可以被限制到毫核(一个核的千分之一)或RAM字节级别。
- cpu
- 限制可超
- Requests:期望能保证的cpu资源量
- Limits:使用cpu资源的上限
- Cpu:0.5 = 500m
- 内存
- 限制不可超,直接kill进程( OOM kill)
ResourceQuta
更丰富和更高的维度控制资源的使用
资源隔离、调度、配额
- Scheduling refers to making sure that Pods are matched to Nodes so that the kubelet can run them
- Eviction is the process of proactively failing one or more Pods on resource-starved Nodes.
Scheduler
监视
新创建的没有分配节点的Pods.
分配
对于调度器发现的每个Pod,调度器将负责为该Pod寻找运行的最佳Node。
调度步骤:
- 节点预选(Predicate):排除完全不满足条件的节点,如内存大小,端口等条件不满足。
- 节点优先级排序(Priority):根据优先级选出最佳节点
- 节点择优(Select):根据优先级选定节点
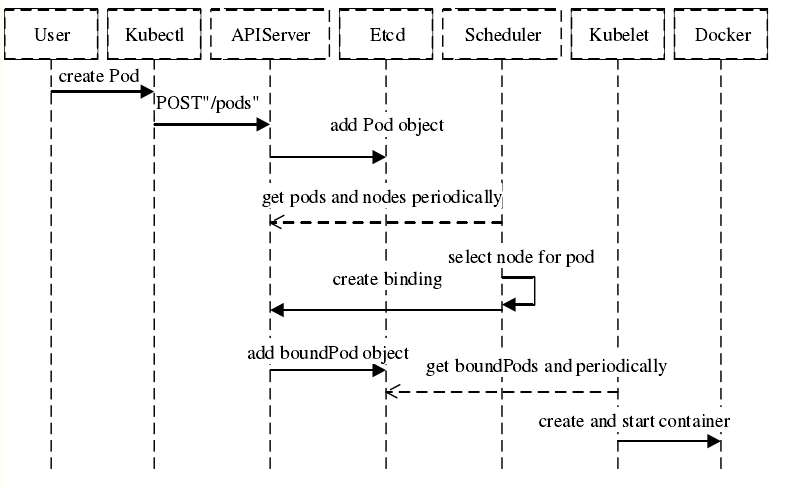
-
首先用户通过 Kubernetes 客户端 Kubectl 提交创建 Pod 的 Yaml 的文件,向Kubernetes 系统发起资源请求,该资源请求被提交到
-
Kubernetes 系统中,用户通过命令行工具 Kubectl 向 Kubernetes 集群即 APIServer 用 的方式发送“POST”请求,即创建 Pod 的请求。
-
APIServer 接收到请求后把创建 Pod 的信息存储到 Etcd 中,从集群运行那一刻起,资源调度系统 Scheduler 就会定时去监控 APIServer
-
通过 APIServer 得到创建 Pod 的信息,Scheduler 采用 watch 机制,一旦 Etcd 存储 Pod 信息成功便会立即通知APIServer,
-
APIServer会立即把Pod创建的消息通知Scheduler,Scheduler发现 Pod 的属性中 Dest Node 为空时(Dest Node=””)便会立即触发调度流程进行调度。
-
而这一个创建Pod对象,在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点
- 节点预选:基于一系列的预选规则对每个节点进行检查,将那些不符合条件的节点过滤,从而完成节点的预选
- 节点优选:对预选出的节点进行优先级排序,以便选出最合适运行Pod对象的节点
- 节点选定:从优先级排序结果中挑选出优先级最高的节点运行Pod,当这类节点多于1个时,则进行随机选择
Kube-scheduler
- 是 Control Plane 的一部分
- Scheduler的默认实现
- 对于每个新创建的pod或其他未调度的pod, kube-scheduler为它们选择一个最优节点来运行。
- 但是,pods中的每个容器对资源都有不同的需求,每个pod也有不同的需求。因此,需要根据具体的调度要求对现有节点进行筛选。
- 在集群中,满足Pod调度要求的节点称为可行节点(feasible nodes)。
- 如果没有合适的节点,pod将保持未调度状态,直到调度器能够放置它。
- 调度器为Pod找到可行节点,然后运行一组函数对可行节点进行打分,然后在可行节点中选择得分最高的节点运行Pod。然后调度器在一个名为binding的进程中通知API服务器(Api server)这个决策。
- 在进行调度决策时,需要考虑的因素包括个别和集体的资源需求、硬件/软件/策略约束、关联和反关联规范、数据位置、工作负载之间的干扰,等等。
Node selection in kube-scheduler 节点选择
为pod选择node需要两步操作:
- Filtering 过滤
- 找到可行地调度Pod的节点集。
- 例如,PodFitsResources过滤器检查候选节点是否有足够的可用资源来满足Pod的特定资源请求。在此步骤之后,节点列表包含任何合适的节点;通常,会有不止一个。如果列表为空,则Pod(还)不能调度。
- Scoring 评分
- 对剩余节点进行排序,以选择最合适的Pod位置。调度器根据活动评分规则为过滤存活下来的每个节点分配一个分数。
最后,kube-scheduler将Pod分配到级别(ranking)最高的节点。如果有多个相同分数的节点,kube-scheduler将随机选择其中一个。
有两种支持的方式配置Filtering和Scoring行为:
- Scheduling Policies 调度策略 :允许您配置用于筛选的谓词和评分的优先级。
- Scheduling Profiles 调度配置 :文件允许您配置实现不同调度阶段的插件,包括:QueueSort、Filter、Score、Bind、Reserve、Permit等。您还可以配置kube-scheduler以运行不同的配置文件。
Kube-proxy
- The Kubernetes network proxy在每个Node上运行。
- 这反映了每个Node上Kubernetes API中定义的服务,可以进行简单的TCP、UDP和SCTP流转发,或者通过一组后端进行TCP、UDP和SCTP的 round robin 调度转发。
- 当前可通过与Docker链接兼容的环境变量找到服务集群的IP和端口,这些环境变量指定了服务代理打开的端口。
- 有一个可选的插件为这些集群ip提供集群DNS。用户必须使用apiserver API创建a service来配置代理。
水平pod弹性收缩
实际用的不多
基于 普罗米修斯 的 HPA
驱逐
-
如果一个节点有10Gi内存,我们希望在内存不足1Gi时候进行驱逐,可以用下面两种方式进行定位驱逐阈值:
memory.available<10%``memory.available<1Gi- 软驱逐(Soft Eviction):配合驱逐宽限期(eviction-soft-grace-period和eviction-max-pod-grace-period)一起使用。系统资源达到软驱逐阈值并在超过宽限期之后才会执行驱逐动作。
--eviction-soft:描述驱逐阈值,例如:memory.available<1.5G``--eviction-soft-grace-period:驱逐宽限期,memory.available=1m30s``--eviction-max-pod-grace-period:终止pod最大宽限时间,单位s- 硬驱逐(Hard Eviction ):系统资源达到硬驱逐阈值时立即执行驱逐动作。
这些驱逐阈值可以使用百分比,也可以使用绝对值,如: --eviction-hard=memory.available<500Mi,nodefs.available<1Gi,imagefs.available<100Gi``--eviction-minimum-reclaim=``"memory.available=0Mi,nodefs.available=500Mi,imagefs.available=2Gi"`````--system-reserved=memory=1.5Gi<br><br> -
驱逐监控间隔
驱逐策略
以下是一些kubelet能用来做决策依据的信号,依据这些信号来做驱逐行为。
-
memory : 内存;
-
nodefs: 指node自身的存储,存储daemon的运行日志等,一般指root分区/;
-
imagefs: 指docker daemon用于存储image和容器可写层(writable layer)的磁盘;

- 策略需要手动在每个node上部署(即时生效)?
- 驱逐后,是否会重启?
磁盘不足
内存不足
- oom killer
最小资源回收
节点资源紧缺情况下系统行为
1. Scheduler行为
Master上的scheduler不再向该节点调度pod,节点状况与调度行为的对应关系如下:
MemoryPressure:不再调度新的BestEffort pod到这个节点` `DiskPressure:不再向这一节点调度pod
2. Node的OOM行为
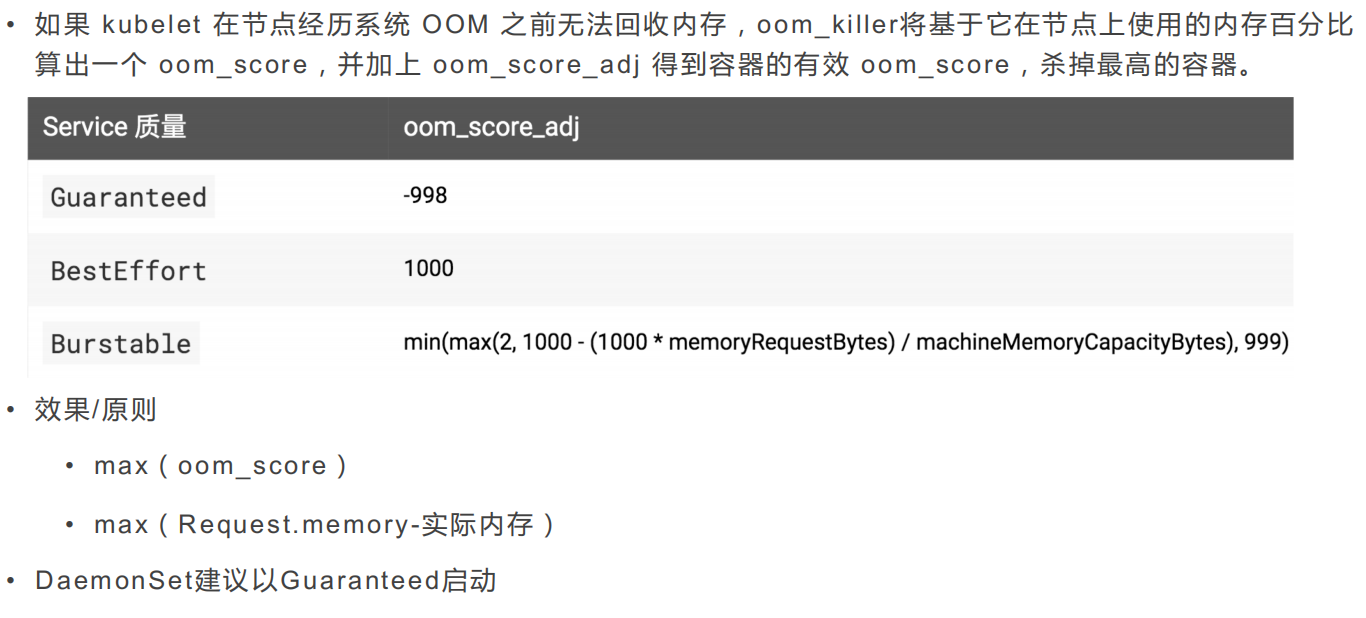
kubelet根据pod的Qos为每个容器设置一个oom_score_adj,如果kubelet无法在系统OOM之前回收足够的内存。则oom_killer会根据内存使用比例来计算oom_score,最后结果和oom_score_adj相加,得分最高的pod将会首先被驱逐。
Pod QoS Class
-
Guaranteed , 指定内存和CPU的请求和限制且相等 ,完全可靠
-
Burstable,不符合Guaranteed,但有资源指定,弹性波动,较为可靠
-
BestEffort,没有资源指定,不可靠
-
按照优先级驱逐
健康检查
- 为了确保Pod处于健康正常的运行状态,Kubernetes提供了两种探针,用于检测容器的状态:
- Liveness Probe :检查容器是否处于运行状态。如果检测失败,kubelet将会杀掉容器,并根据重启策略进行下一步的操作。如果容器没有提供Liveness Probe,则默认状态为Success;
- 是否还活着
- 可以捕获死锁,应用程序正在运行,但无法取得进展。在这种状态下重新启动容器可以继续存活。
- Readiness Probe :检查容器是否已经处于可接受服务请求的状态。如果Readiness Probe失败,端点控制器将会从服务端点(与Pod匹配的)中移除容器的IP地址。Readiness的默认值为Failure,如果一个容器未提供Readiness,则默认是Success。
- 来确定容器是否已经就绪可以接收流量过来了
- 当一个应用服务有大文件加载时,这种情况下不允许接受用户访问,readiness probe就不会对这类型的程序启动服务。
- Liveness Probe :检查容器是否处于运行状态。如果检测失败,kubelet将会杀掉容器,并根据重启策略进行下一步的操作。如果容器没有提供Liveness Probe,则默认状态为Success;
- kubelet在容器上周期性的执行探针以检测容器的健康状态,kubelet通过调用被容器实现的处理器来实现检测,在Kubernetes中有三类处理器:
- ExecAction :在容器中执行一个指定的命令。如果命令的退出状态为0,则判断认为是成功的;
- TCPSocketAction :在容器IP地址的特定端口上执行一个TCP检查,如果端口处于打开状态,则视为成功;
- HTTPGetAcction :在容器IP地址的特定端口和路径上执行一个HTTP Get请求使用container的IP地址和指定的端口以及请求的路径作为url,用户可以通过host参数设置请求的地址,通过scheme参数设置协议类型(HTTP、HTTPS)如果其响应代码在200~400之间,设为成功。
- 健康检测的结果为下面三种情况:
- Success :表示容器通过检测
- Failure :表示容器没有通过检测
- Unknown :未知,不做处理