Mysql优化
三板斧
- 慢查询日志
- 分场景开启,一般在自测,内测前开启
- 生产环境不建议开启
- explain执行计划
- show profile
表与索引的存储方式
B+Tree,高度及广度带来的问题。这个单独写篇文章进行描述。
索引
大多数情况,一个简单的sql只能用到一个索引
- 简单:不包含子查询或者JOIN的sql
mysql内部进行索引带价计算,选择区分度大的索引,和SQL里面and的顺序无关
建立合适的索引
Index Selectivity = count(distinct column) / count(*)
- 索引要能过滤大部分数据
- 使用区分度高的列作为索引
- 区分度越高,索引树的分叉也就越多,一次性找到的概率也就越高
- 尽量使用字段长度小的列作为索引
- 使用数据类型简单的列(INT型,固定长度)
- 选用NOT NULL的列
- 含有空值的列很难进行查询优化,用0、一个特殊的值或者一个空字符串代替空值
- 尽量的扩展索引,不要新建索引
- 比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可,这样也可避免索引重复
找到合适的索引
| SQL | 结果 |
|---|---|
| Select count(distinct a) from tuser | 98735 |
| Select count(distinct b) from tuser | 1,235 |
| Select count(distinct c) from tuser | 201 |
| Select count(distinct d) from tuser | 2 |
建议:IX a > IX b > IX c > IX d
是否需要给所有字段加索引?
不需要!
- 业务逻辑中用到的sql尽可能地通过索引的方式访问数据
- 特殊意义的字段,建议加上索引
- 例如:create_time 记录创建时间 update_time 记录修改时间
- 慢查询的sql,优先判断是否可以通过添加索引或者调整索引结果解决
EXPLAIN
> explain select * from tg_order limit 1;
| Column | JSON Name | Meaning |
|---|---|---|
id |
select_id |
The SELECT identifier |
select_type |
None | The SELECT type |
table |
table_name |
The table for the output row |
partitions |
partitions |
The matching partitions |
type |
access_type |
The join type |
possible_keys |
possible_keys |
The possible indexes to choose |
key |
key |
The index actually chosen |
key_len |
key_length |
The length of the chosen key |
ref |
ref |
The columns compared to the index |
rows |
rows |
Estimate of rows to be examined |
filtered |
filtered |
Percentage of rows filtered by table condition |
Extra |
None | Additional information |

- select_type(表的读取顺序和方式)
- Simple:简单的查询(没有union或子查询)
- Primary:最外层的查询(有union或子查询)
- derived:衍生表查询(from语句中的子查询)
- Extra(更多信息)
- using filesort: mysql需要进行额外的排序来获取数据
- using temporary:mysql需要创建临时表来存放数据
- 可能的索引与实际使用的索引
- type
- 从优到差排序如下:
- const:只匹配一行,根据主见或唯一键进行查询
- eq_ref: 单行关联查询,根据主键或唯一键进行join
- 触发条件:只匹配到一行的时候。除了
system和const之外,这是最好的连接类型了。当我们使用主键索引或者唯一索引的时候,且这个索引的所有组成部分都被用上,才能是该类型。 - 在对已经建立索引列进行
=操作的时候,eq_ref会被使用到。比较值可以使用一个常量也可以是一个表达式。这个表达示可以是其他的表的行。 - A表的字段a是主键或唯一键 join了B表的主键或唯一键字段b
- A.a = B.b
- 触发条件:只匹配到一行的时候。除了
- ref:单行关联查询,根据普通索引进行查询或join
- 触发条件:触发联合索引最左原则(不知道的搜下),或者这个索引不是主键,也不是唯一索引(换句话说,如果这个在这个索引基础之上查询的结果多于一行)。
- 如果使用那个索引只匹配到非常少的行,也是不错的。
- A表的字段a是主键或唯一键 join了C表的普通索引字段c
- A.a = C.c
- range:索引范围查询
- index:索引扫描查询
- all:全表扫描查询
- 从优到差排序如下:
- possible_keys
- 优化器可能用到的索引
- key
- 实际用到的索引,没有则为null
- rows
- 预估检查行数
- type
http://dev.mysql.com/doc/refman/5.0/en/explain-output.html
前缀索引。eg: like ‘%xxx%’ like ‘_xxx%’
现在有个user表,列 family_name varchar(50) 保存的是英文姓氏(我也想用中文姓名来举例,但是不大适合,看下去就明白了。。。)
要取得设置前缀索引最理想的"prefix_length",我们首先要取得整列的选择性,如下:
SELECT COUNT(DISTINCT family_name)/COUNT(*) FROM user;
假设这里得到值是0.188。
然后我们继续去看看该列前1个字符的选择性又是多少
SELECT COUNT(DISTINCT LEFT(family_name,1))/COUNT(*) FROM user;
假设这里得到的结果是0.532,和整列的选择性出入太大,不可取,继续:
SELECT COUNT(DISTINCT LEFT(family_name,2))/COUNT(*) FROM user;
SELECT COUNT(DISTINCT LEFT(family_name,3))/COUNT(*) FROM user;
...
假设直接到“prefix_length”为5时,得到的值为0.189,非常接近!
而取6时得到的值为0.18891,这个选择性和5并没有太大的偏差。
再结合减少索引文件大小的这个思路
“prefix_length”值设置为5才是此处设置前缀索引的最优方案!
选择性讲完,还得再讲清楚这个前缀索引该怎么用!
书接上面的栗子~
正确的用法如下:
SELECT * FROM user WHERE family_name LIKE "lee%";
SELECT * FROM user WHERE family_name LIKE "david%";
以下则用不上该索引:
SELECT * FROM user WHERE family_name LIKE "_ee%";
SELECT * FROM user WHERE family_name LIKE "%en%";
SELECT * FROM user WHERE family_name LIKE "%ar%";
注意:SQL的模式缺省是忽略大小写的!
另外,“_”代表一个字符,“%”代表任意多个字符
最左原则

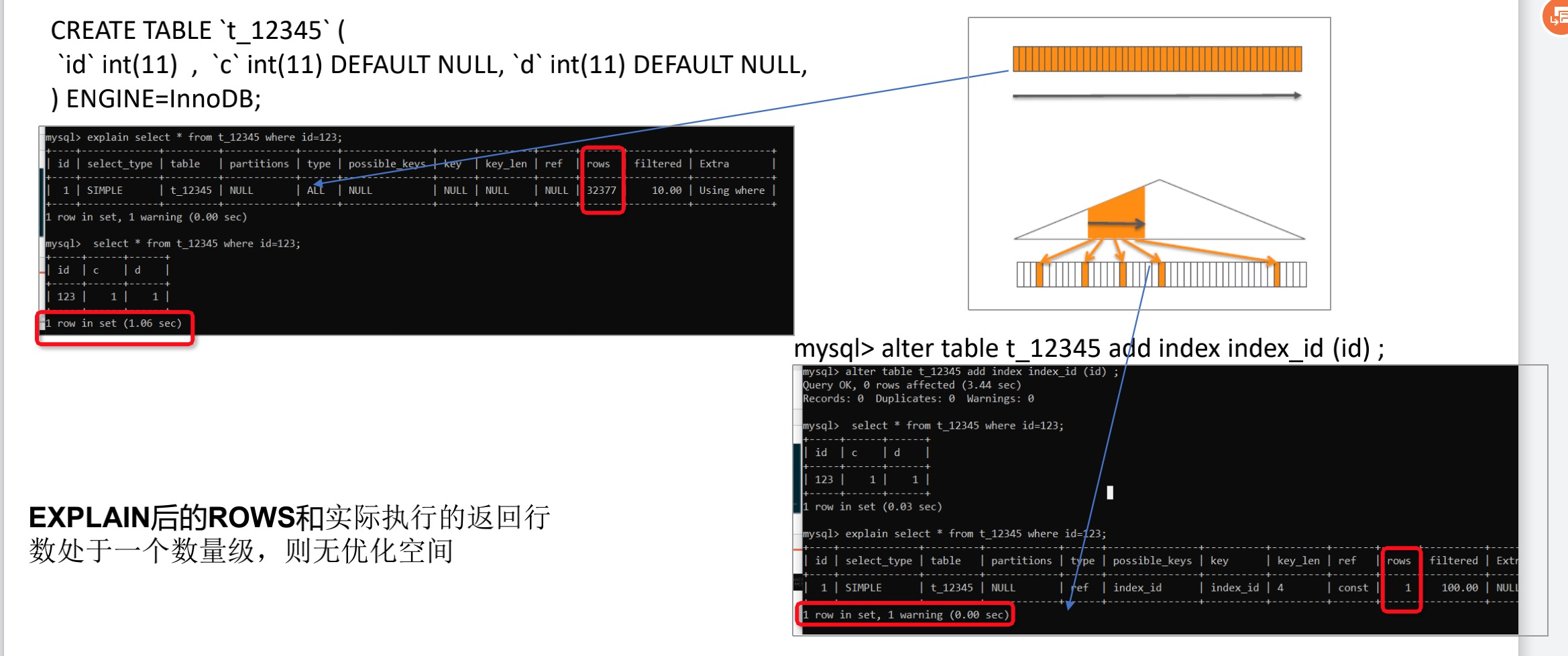
如何判断SQL有无优化空间
EXPLAIN后的ROWS和实际执行的返回行数处于一个数量级,则无优化空间
问题,MySQL使用索引是不是一定比不使用索引性能好?
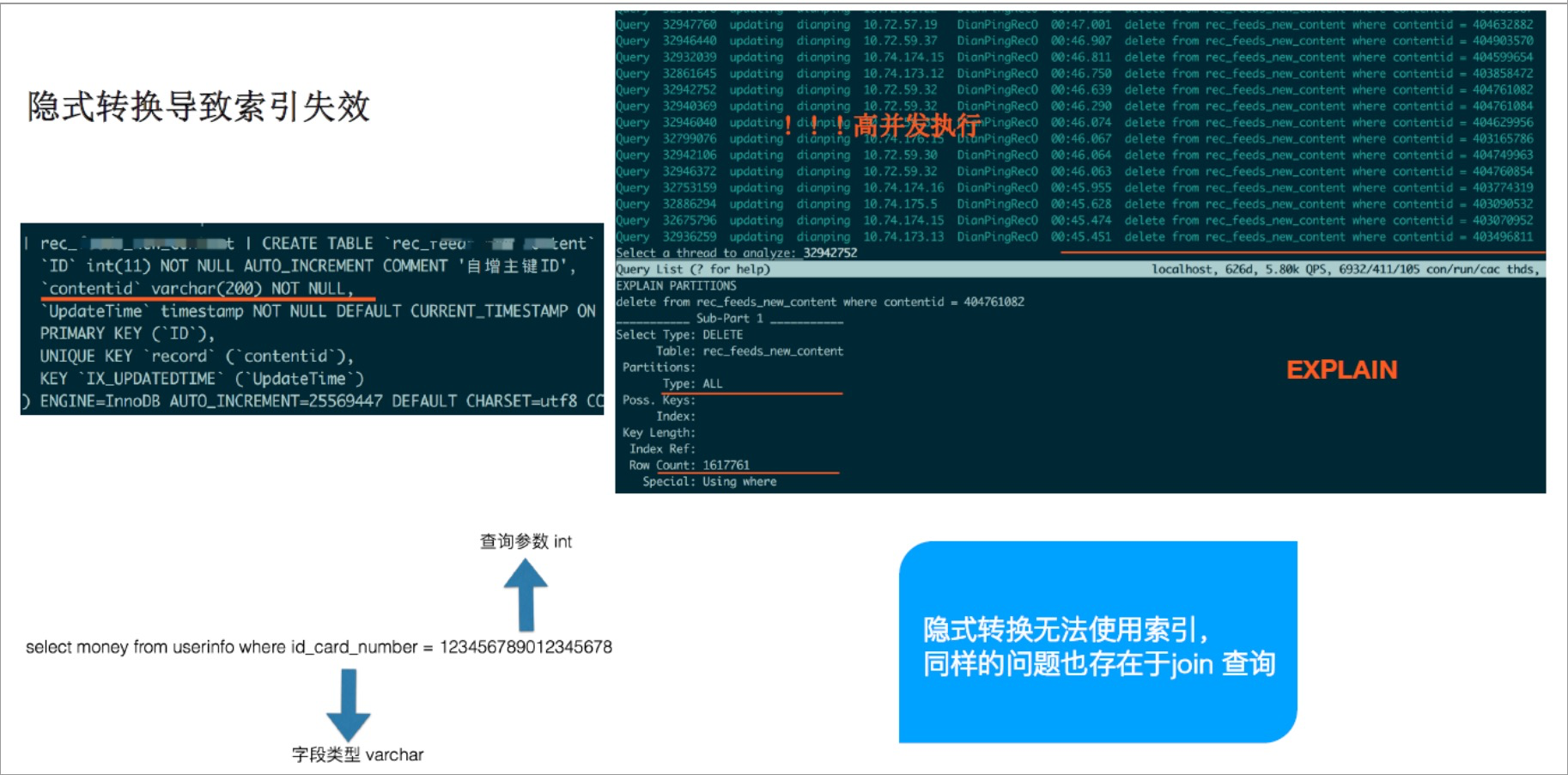
防止隐式转换
线上如何安全加索引
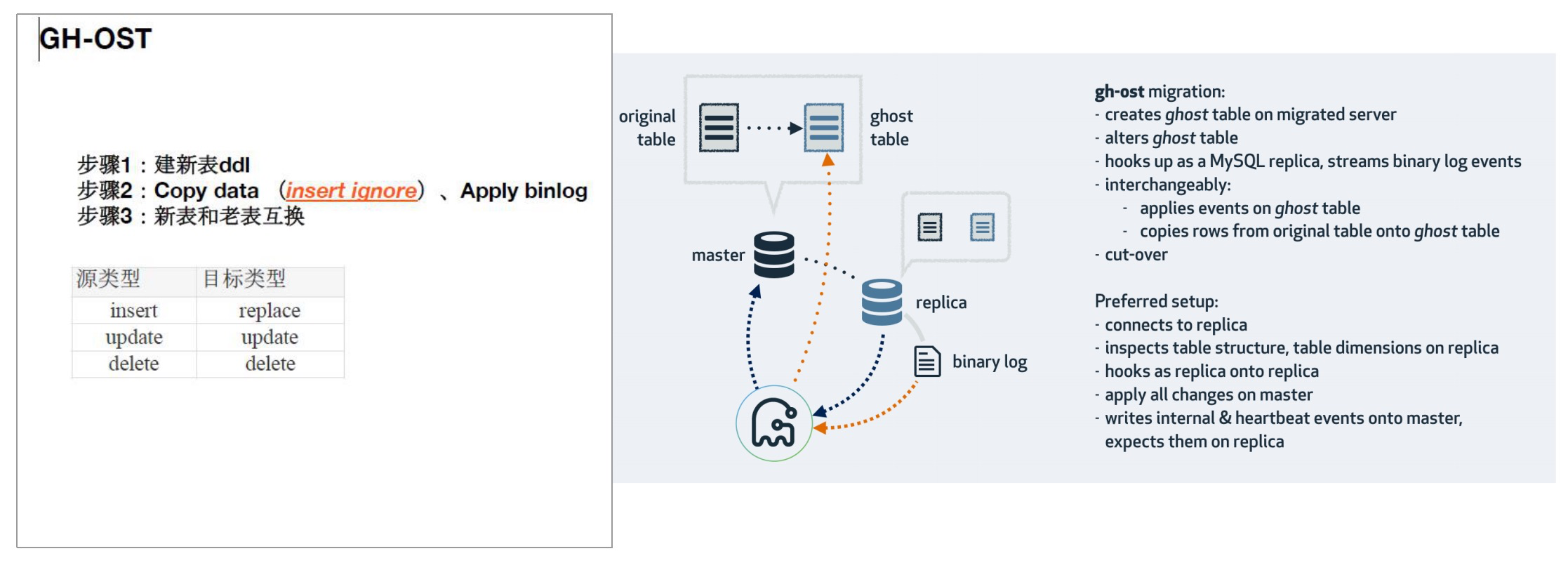
MySQL8.0的不可见索引
INVISIBLE INDEX
不可见索引或者叫隐藏索引。就是对优化器不可见,查询的时候优化器不会把它作为备选。
使用场景
需要安全的删除索引,但不确认索引是否被其他的SQL逻辑用到。
使用
• alter table f1 alter index idx_a invisible;
• set @@optimizer_switch = ‘use_invisible_indexes=on’
如何用好索引
- 禁⽌在Where条件的列名上使⽤函数
- 禁⽌使⽤存储过程、存储函数、触发器和视图
- 尽量不要在数据库⾥做运算
- 尽量不要做‘%’前缀模糊查询,如like ‘%name‘
- 不要使⽤⼤偏移量的limit分页
- update/delete尽量根据主键进⾏操作
用好索引覆盖

索引优化建议
- 禁止使用Select * ,*用所需字段代替.
- 禁止使用Select For Update.
- 禁止在Where条件的列名上使用函数.
- 禁止使用子查询.
- update/delete只能单表操作,不允许多表关联,不允用子查询,且要带where条件.
- insert语句要显式指定插入的列名,且不允许使用insert …. select的形式.
- 禁止使用存储过程、存储函数、触发器和视图.
- 避免使用Delete,用Update代替做软删除.
- 避免使用Or,用Union代替.
- 尽量不要在数据库里做运算.
- 尽量不要做‘%’前缀模糊查询,如like ‘%name’.
- 不要使用大偏移量的limit分页.
- 批量insert语句最好采用bulk insert的方法,如insert into table(xxx) values (xxx),(xxx),每个批次以执行时间小于100ms为原则
- update/delete尽量根据主键进行操作.
- 尽量减少count()的使用,尤其是用来频繁获取全表记录数.
- 使用group by时,如无排序的需求,建议加order by null.
- Join中使用的关联字段使用统一数据类型.
- 尽量不要在查询语句中指定强制索引force index.
慢查询发现
慢查询日志重要变量
SHOW GLOBAL VARIABLES LIKE '%long_query_time%';
SHOW GLOBAL VARIABLES LIKE '%slow_query_log_file%';

慢查询日志例子:
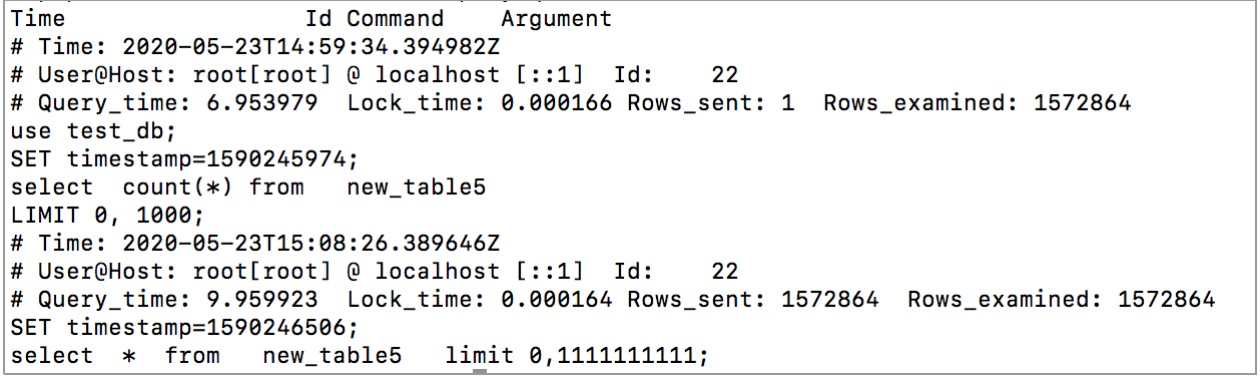
- Query_time: duration
The statement execution time in seconds.
- Lock_time: duration
The time to acquire locks in seconds.
- Rows_sent: N
The number of rows sent to the client.
- Rows_examined:
The number of rows examined by the server layer (not counting any processing internal to storage engines).
Join
MySQL是只支持一种JOIN算法Nested-Loop Join(嵌套循环链接)
不像其他商业数据库可以支持哈希链接和合并连接, 不过MySQL的Nested-Loop Join(嵌套循环链接)也是有很多变种, 能够帮助MySQL更高效的执行JOIN操作:
Simple Nested-Loop Join
row scan -> r1 -> match (s1,s2,s3,sN) -> r2 -> (…) -> rN
从驱动表中取出R1匹配S表所有列,然后R2,R3,直到将R表中的所有数据匹配完,然后合并数据,可以看到这种算法要对S表进行rN * sN 次访问,虽然简单,但是相对来说开销还是太大了
性能优化
全表扫描
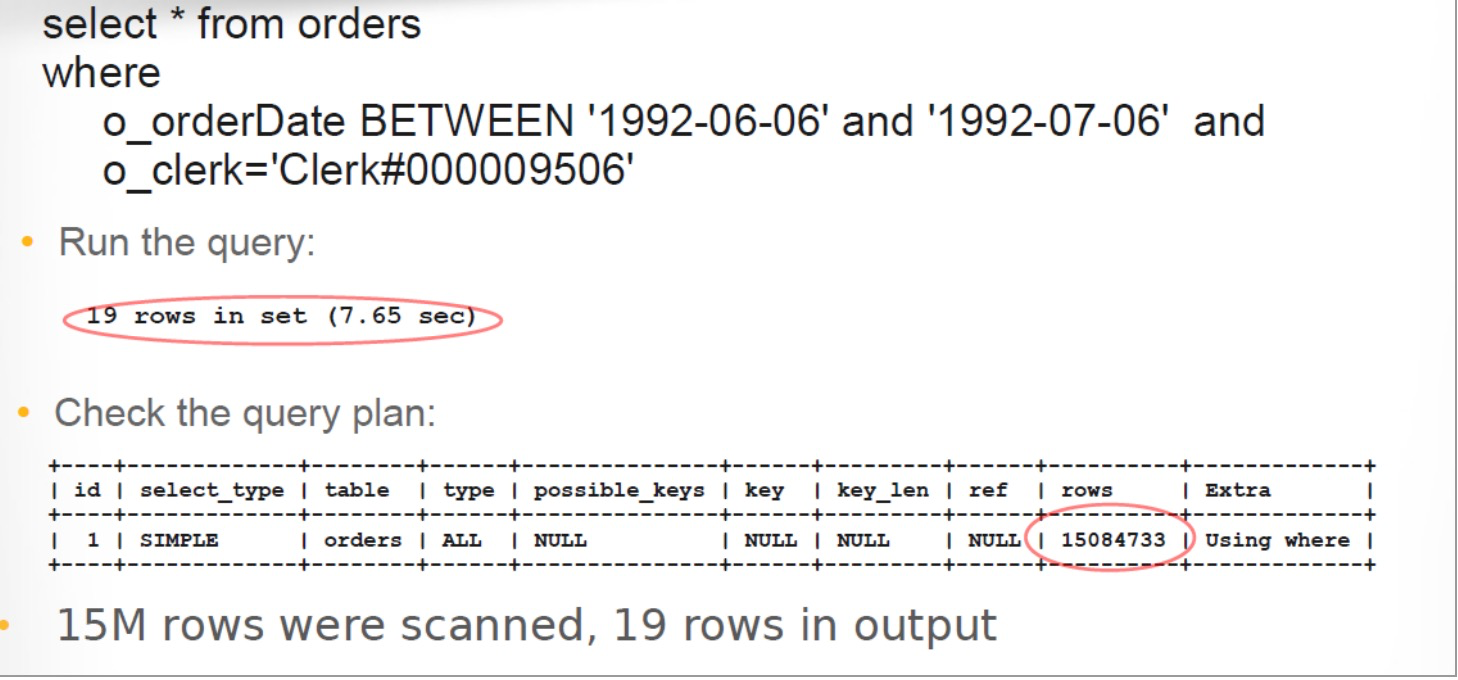
1500万数据被扫描,19条数据匹配
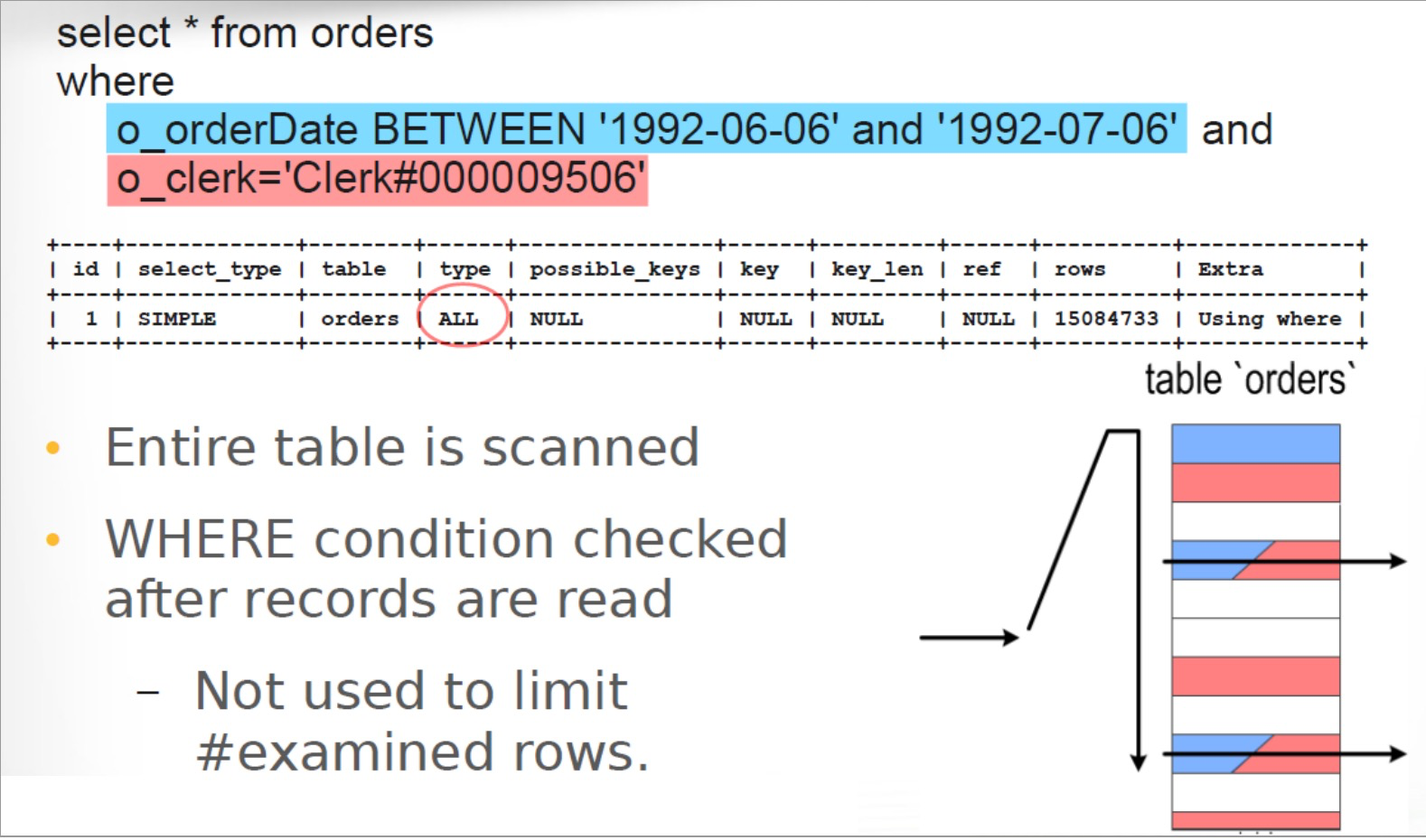
先扫描后匹配,扫面范围没有限制(全量)
Range
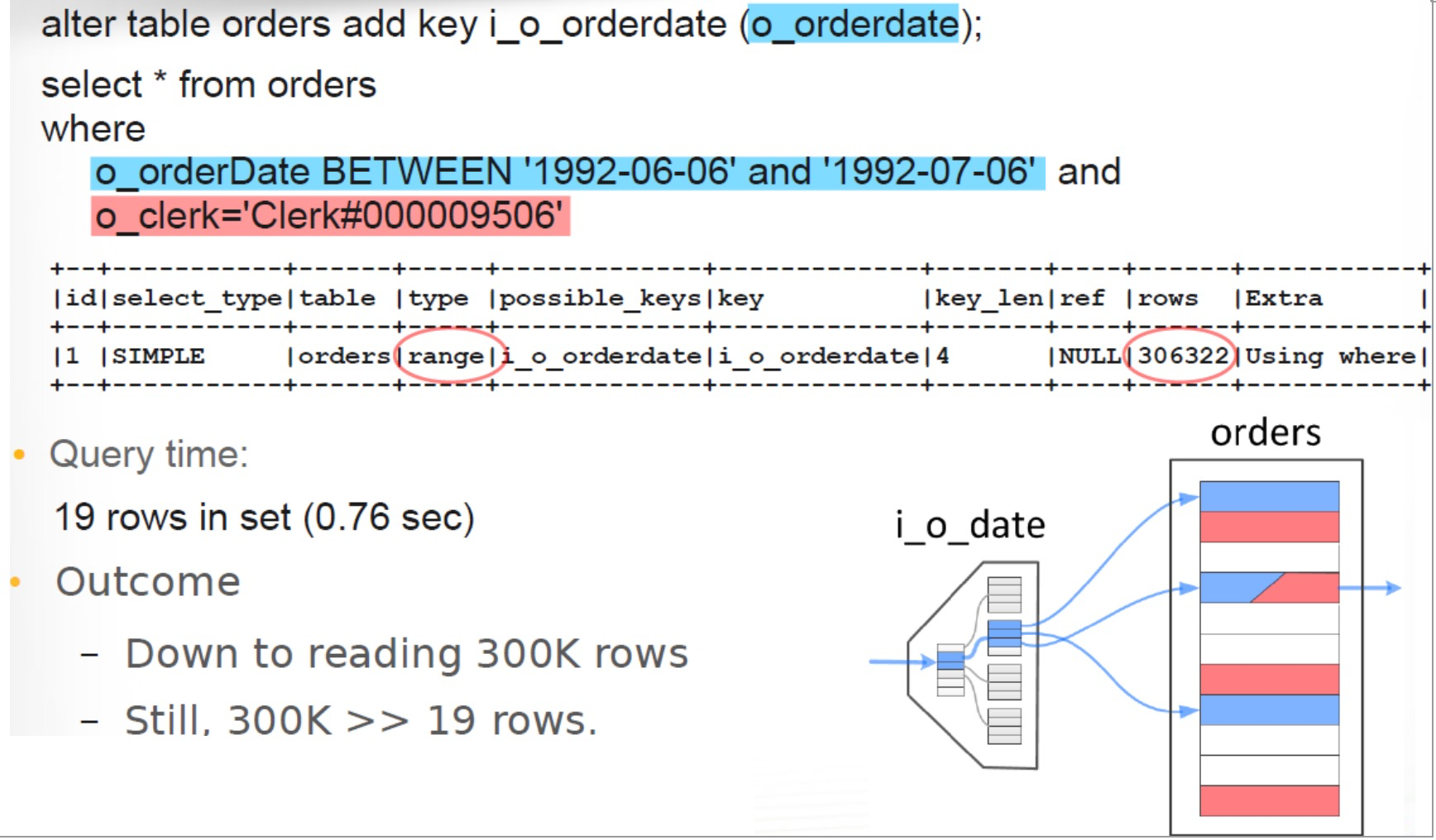
扫面范围降低到300K行
ref
explain select * from orders where o_orderDate BETWEEN '1992-06-06' and '1992-07-06' and
o_clerk='Clerk#000009506';
Ref选择性
alter table orders add index i_o_clerk (o_clerk);

trace 工具
mysql最终是否选择走索引或者一张表涉及多个索引, mysql最终如何选择索引,可以通过trace工具来一查究竟,开启trace工具会影响mysql性能,所以只能临时分析sql使用,用完之后需要立即关闭。
SET SESSION optimizer_trace="enabled=on",end_markers_in_json=on; --开启trace
SELECT * FROM employees WHERE name > 'a' ORDER BY position;
SELECT * FROM information_schema.OPTIMIZER_TRACE;
"join_preparation": { --第一阶段:SQl准备阶段
"condition_processing": { --条件处理
table_scan": { --全表扫描情况
"rows": 3, --扫描行数
"cost": 3.7 --查询成本
"potential_range_indices": [ --查询可能使用的索引
"analyzing_range_alternatives": { ‐‐分析各个索引使用成本
"index_only": false, ‐‐是否使用覆盖索引
"rows": 3, --‐‐索引扫描行数
"cost": 4.61, --索引使用成本
"chosen": false, ‐‐是否选择该索引
SET SESSION optimizer_trace="enabled=off"; -- 关闭trace
性能优化
多表链接优化
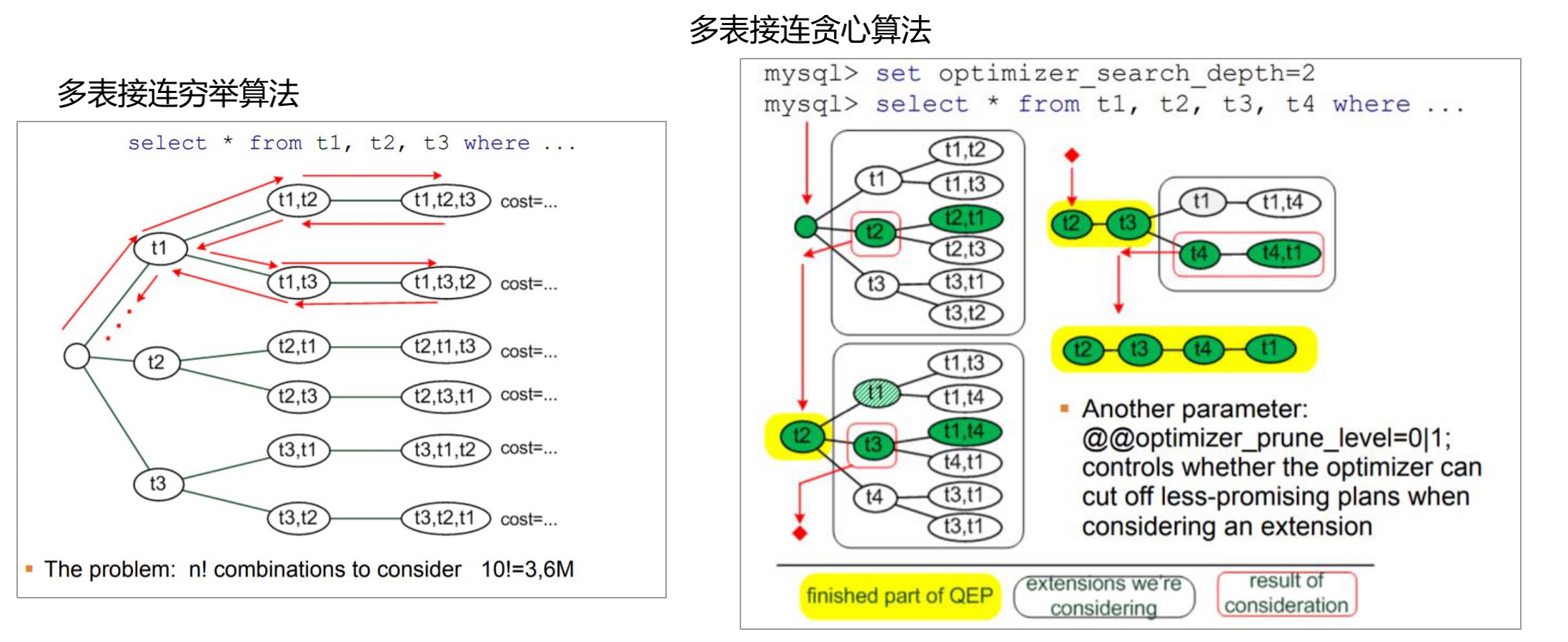
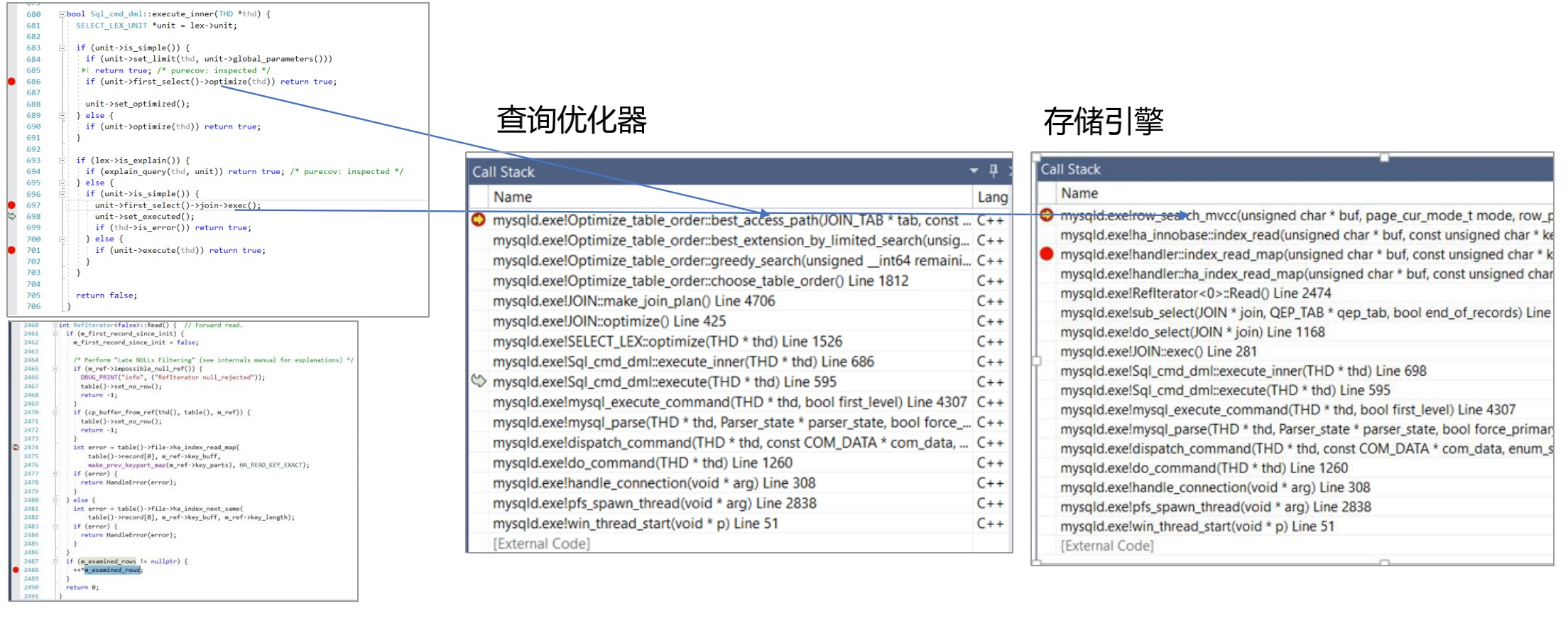
查询优化器总体架构
优化器主要优化阶段
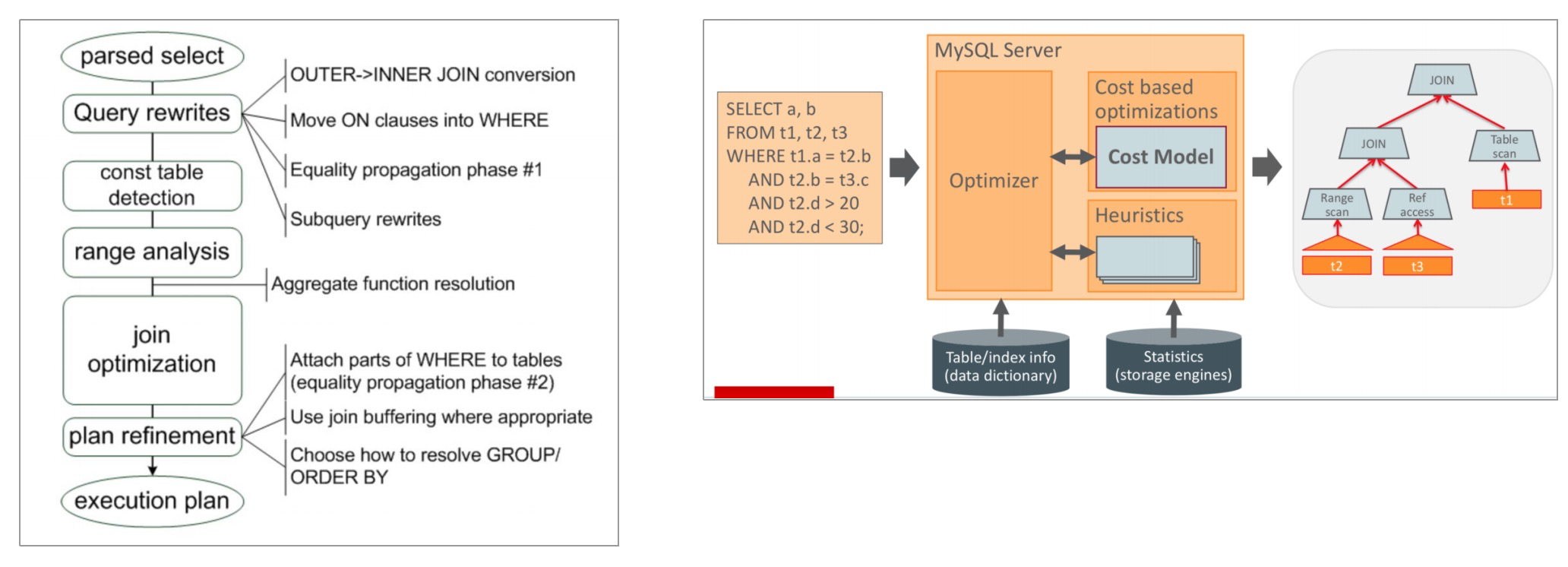
查询优化器源码调试
select * from t_12345 where id=123;